Functional Programming with Kotlin and Arrow Part 2: Categories and Functors
In this functional programming tutorial, you’ll learn what category theory is, see how to apply it to programming, and learn how to make use of Functors with Arrow. By Massimo Carli.
When encountering Functional Programming (FP) for the first time, you may ask yourself: “So what?”
As in the previous tutorial of this series, the main challenge is to understand abstract concepts, and then apply them to real use cases.
This is especially true when you study one of the most abstract branches of math: category theory. This is an abstract topic, and it’s all about composition, which you might recall are the two superpowers of the FP hero.

Simplifying this theory through a practical approach is also the goal for this tutorial, where you’ll learn:
- What category theory is.
- How to apply it to programming.
- Where the Arrow name came from.
- What a Functor is and how it can be useful.
- The type constructor and the Kind type.
- What a typeclass is.
- How to use List and Maybe as functors
Again, you have a lot to get through, so let’s get started :]
Getting Started
Before you begin, download the tutorial materials using the Download Materials button at the top or bottom of this page.
You’ll see two projects in there, one containing the starter project, and another with the final code. Open the starter project in IntelliJ IDEA, where you’ll see a Gradle project with these four modules:
- functions: Contains some simple, pure functions and related tests.
- custom-maybe: You will use this to create your own implementation of the Maybe Functor.
- data-types: Initially empty, you will write code to implement an Arrow-based version of Maybe.
- app: The final app module used to run your Arrow code.
To keep the Arrow-based implementation separated from your own, the custom-maybe module depends only on the functions module. For the same reason, the app module depends on data-types, which itself depends on functions.
The app, custom-maybe and data-types modules also define a dependency on the Arrow framework. This is the start of your second journey from Object Oriented Programming (OOP) to Functional Programming (FP). Again, fasten your seat belts!
What Is a Category?
Category theory is one of the most abstract branches of mathematics, and it’s an important one because programming is one of its main applications. In this tutorial, you’ll learn the concepts of this theory that can be useful when you apply FP to your code.
What is a category? A category is a bunch of objects, with connections between them called morphisms, plus some rules.
You can think of an object like a dot with no properties and no further way to be decomposed. If the object had properties, think of it as a set of them. A morphism is an arrow (rings a bell?) between two objects. Every object of a category must have at least a single morphism — identity — which connects it with itself. As you can see in the following image, different objects can also have a morphism between them, though this is not mandatory:
Objects and Morphisms
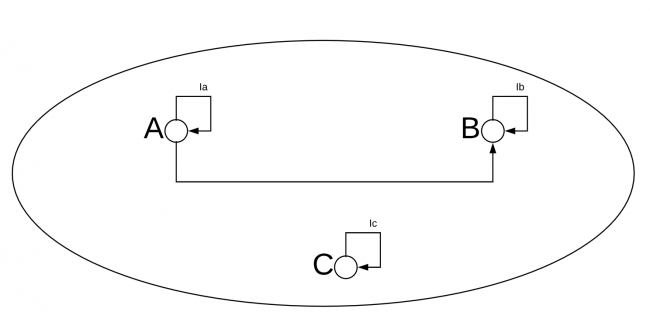
Objects and Morphisms
In this image, you can see a category with three objects (A, B and C), their identity morphisms (Ia, Ib and Ic) and a morphism between A and B.
You can have multiple morphisms between two objects A and B. You can even have multiple identities, and therefore multiple morphisms between an object and itself.
Composition
Objects and morphisms are not enough to define a category: An operation called composition is also required to exist for the morphisms. To understand it, take a look at the following image:
Function composition
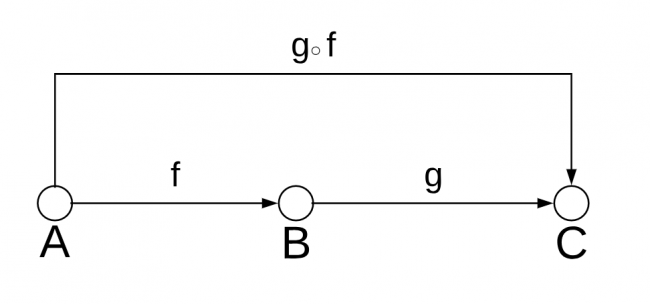
Function composition
Here you have a morphism, f, from A to B and a morphism, g, from B to C.
In this case, a category must have another morphism, which you call g after f, from A to C which is the composition of f and g. As in the image, you represent the composition using the small circle ○. Note that the image doesn’t show the identities, as those are assumed to exist for each object.
Composition has to have the property of associativity which, given three morphisms f, g and h, you can represent as:
h ○ (g ○ f) = (h ○ g) ○ f
Also, in this case, you can use identities in a simple way to replace each morphism.
The Category of Types and Functions
That “So what?” question might be popping up again. Let’s think about what objects and morphisms can correspond to in programming terms.
What if objects are types and morphisms are functions? You have to prove that this is a category. Given a type T you need an identity, which would be a function that maps values of that type to objects of the same type. In Kotlin you can always write something like:
fun <T> identity(value: T) = value
In this case, you return the same value as the input value. You’ve used Kotlin’s one-line function syntax, in which the return type T is inferred by the compiler.
Remember, what matters is the return type, which must be the same as the input parameter’s type. Because of this, you might have infinite identities. However, to prove that this is a category, you only need one.
With that done, you need to prove that you have composition with associativity. You’ve seen composition in the previous tutorial of the series, which Arrow represents like this:
inline infix fun <B, C, A> ((B) -> C).compose(crossinline f: (A) -> B): (A) -> C = { a: A -> this(f(a)) }
If you have a function g of type (B) -> C and a function f of type (A) -> B you can compose them and get a function g ○ f of type (A) -> C.
In the previous snippet, you apply the compose function as an infix operation on g and f, getting a new function as the return value.